当不满足更常见过程的分布假设时,使用非参数方法分析数据。例如,许多统计程序假设基础误差分布是高斯分布,因此广泛使用均值和标准差。当误差分布未知时,应用非参数统计检验可能更安全。
Statgraphics 中的非参数方法是应用经典检验的相同过程中的选项。这些非参数统计方法根据其应用分类如下。
| 应用 | Statgraphics Centurion 18/19 | Statgraphics Sigma express | Statgraphics stratus | Statgraphics Web 服务 | StatBeans |
|---|---|---|---|---|---|
| 拟合优度检验 |  | | | | |
| 在一个样本或配对样本中进行推理 | | | | | |
| 比较两个样本 | | | | | |
| 比较多个样本 | | | | | |
| 相关分析 | | | | | |
| 关联测试 | | | | | |
| 随机性测试 | | | | | |
| 密度估计 | | | | | |
| 曲线拟合 | | | | | |
| 非参数公差限制 | | ||||
| 神经网络 | | ||||
| Polish中位数 | | ||||
| 克里金法 | |
拟合优度检验
拟合优度检验用于将观测值(定量或分类)的发生频率与概率模型进行比较。具体检验包括卡方拟合优度检验、Kolmogorov-Smirnov 检验和 Anderson-Darling 检验。

更多: 频率表.pdf, 列联表.pdf, 分布拟合(未经审查的数据).pdf
在一个样本或配对样本中进行推理
当从单个总体或两个总体的配对样本中收集数据时,通常需要估计和检验这些总体的参数。单变量分析程序将使用符号检验或符号等级检验来检验总体中位数的值或两个中位数之间的差异。它还将使用bootstrapping创建均值、标准差和中值的区间估计值,bootstrapping是一种通过从观察到的数据值创建许多新样本来获得估计值的过程。

比较两个样本
当通过抽取独立样本从两个总体中收集数据时,可以创建检验统计量,而无需假设总体中的观察值呈正态分布。双样本比较程序执行Mann-Whitney (Wilcoxon)检验以比较中位数,并执行双边Kolmogorov-Smirnov检验以比较整个分布。

比较多个样本
当从两个以上的人群中收集数据时,多样本分析程序可以使用Kruskal-Wallis检验、Mood的中位数检验或Friedman检验来检验人群中位数之间的显著差异。它还可以创建缺口盒须图,该图具有这样的性质,即任何两个中值缺口不重叠的样本都表明其各自总体中值之间存在统计学上的显著差异。

更多: Multiple Sample Comparison.pdf
相关分析
多变量分析程序将使用皮尔逊积差相关系数计算变量对之间的相关性,或使用肯德尔或斯皮尔曼方法计算等级相关性。右边的表格显示了4个人口统计学变量的估计相关性、样本大小和近似P值。
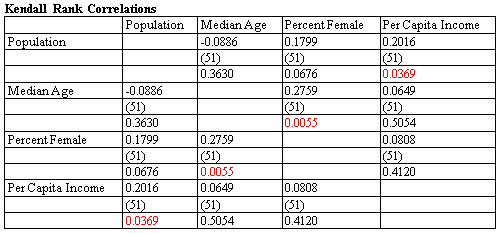
更多:Multiple Variable Analysis.pdf
相关分析
对于分类数据,可以在列联表程序中计算两个因素水平之间的各种关联度。左边的表格显示了典型的2 x2表格的统计数据。
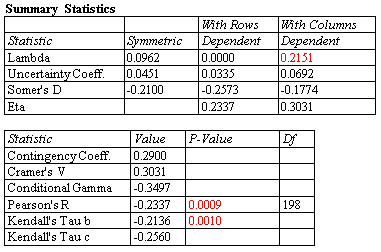
更多:列联表.pdf
随机性测试
对于顺序数据,可以执行运行测试以确定数据是否来自随机过程。“运行图”过程通过计算高于和低于中位数的运行次数以及计算向上和向下运行的次数来执行测试。

更多:运行图.pdf
密度估计
Statgraphics 中的几个过程计算密度迹线。给定一列连续数值数据,密度迹线提供从中采样数据的总体的概率密度函数的非参数估计。它是通过计算落在固定宽度窗口内的观测值数来创建的,该窗口在数据范围内移动。

曲线拟合
简单回归过程提供了最小二乘法的 2 个备选方案,用于拟合与 Y 和 X 相关的线性和非线性曲线。这些方法包括最小化拟合曲线周围绝对偏差的总和,以及使用 3 组中位数的 Tukey 方法。

更多:简单回归.pdf
非参数公差限制
统计容差限给出了 X 的值范围,使得数据样本所来自的总体的 P % 在该范围内的置信度为 100(1-a)%。非参数限制不假定数据来自任何特定分布。但是,它们不如基于特定分布假设的精确或灵活。

更多: 统计公差限(观测值).pdf
神经网络
概率神经网络分类器 (PNN) 实现了一种非参数方法,用于根据 p 个观测到的定量变量将观测值分类为 g 组之一。它不是对每个组内变量分布的性质做出任何假设,而是根据该组的相邻观测值在所需位置构建每个组的密度函数的非参数估计。该估计值是使用 Parzen 窗口构建的,该窗口根据每个组与指定位置的距离对每个组的观测值进行加权。

更多: Neural Network Classifier.pdf
Polish中位数
Polish中位数过程为双向表中包含的数据构建模型。该模型以公共值、行效应、列效应和残差表示每个单元格的内容。尽管使用的模型与使用双向方差分析估计的模型相似,但模型中的项是使用中位数而不是均值来估计的。这使得估计值更能抵抗可能存在的异常值。
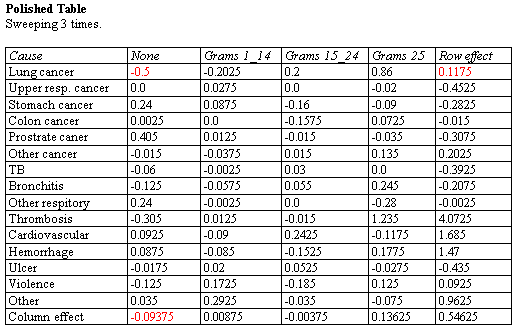
更多: Polish波兰语.pdf
克里金法
克里金法是一种广泛用于分析地理空间数据的过程。给定在二维区域内不同位置对变量进行的一组测量值,将得出该变量在整个区域中的值的估计值。主要输出是估计值的映射,以及估计值的方差。

更多: Kriging.pdf, Kriging Statlet.pdf