估计故障时间的分布是一个重要的统计问题。故障时间数据在许多情况下都会出现。在医学上,人们可能会对一种新疗法可以延长患者的生命多长时间感兴趣。对于制成品,人们可能会对物品在各种条件下的预期使用寿命感兴趣。通常,故障时间可以表示为一个或多个预测变量的函数,从而导致回归模型的创建。
统计模型
例如,考虑设计为在指定电压和温度下工作的电子电路的情况。工程师对估计电路可能正常运行的时间感兴趣。更具体地说,工程师想知道平均故障时间 (MTTF) 以及故障时间分布的各个百分位数。但是,如果电路设计良好,则在正常工作条件下测试电路可能不切实际,因为观察足够多的故障需要很长时间才能有意义。相反,测试通常会在更高的温度和电压下进行,而故障时间更短。然后使用拟合回归模型将结果外推到正常操作条件。
Statgraphics 版本 19.6 包括用于估计常用加速寿命测试模型的新程序。可能适合两类一般模型:
1. location scale models(位置比例模型) – 将故障时间表示为一个或多个加速因素加上误差项的函数的模型。在这种情况下,通常假定故障时间遵循正态、逻辑或最小极值分布。
2. log-location-scale-models – 模型,其中故障时间的对数表示为一个或多个加速因素加上误差项的函数。在这种情况下,通常假定故障时间遵循对数正态分布、对数逻辑分布、指数分布或威布尔分布。
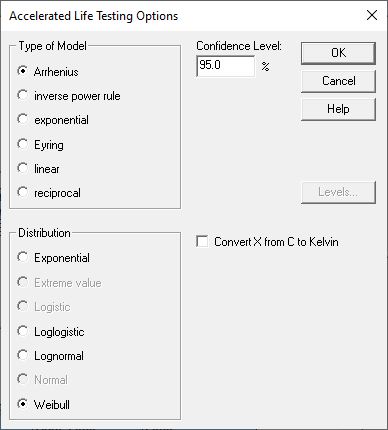
还有几种常用的加速度模型,如下面的对话框所示:
如果加速变量是温度,则通常使用Arrhenius模型,该模型采用以下形式:
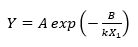
其中 Y 是故障时间,X1是以开尔文度为单位的温度 (°C + 273.15),k = 0.00008617(玻尔兹曼常数),A 和 B 是两个未知参数。取两边的对数表明,对数失效时间与温度的倒数呈线性关系:
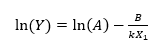
通过在上述等式中添加附加项,可以引入其他加速因素,例如电压。
示例数据
举个例子,考虑下面显示的数据:
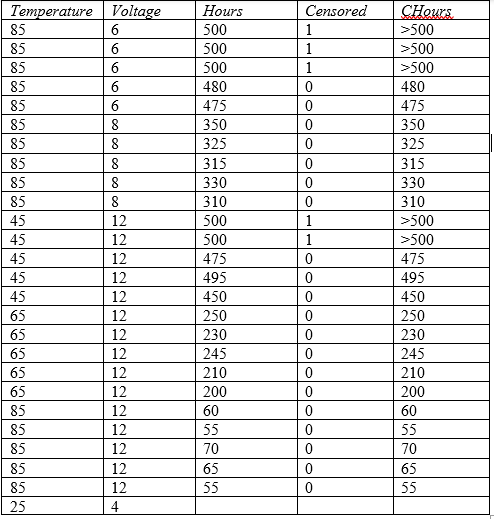
在温度 = 45、65 和 85 摄氏度以及电压 = 6、8 和 12 伏时收集数据。小时数表示每个项目失败之前的时间,如果项目在 500 小时后仍未失败,则表示 500。对于实际故障时间,Censored 设置为 0,如果项目在 500 小时内未发生故障,则设置为 1。还显示了一个名为 CHours 的附加列,这是一个特殊的删失数值数据列。在该列中,右删失值由表示法 >500 表示。
该研究的目的是估计温度 = 25 和电压 = 4 的正常工作条件下的故障时间分布。请注意,这些值已添加到数据表的底部,而“小时”单元格留空。Statgraphics ALT(加速寿命测试)程序将自动将该因素组合识别为需要预测的因素组合。
“数据输入”对话框
ALT 数据输入对话框采用以下形式:
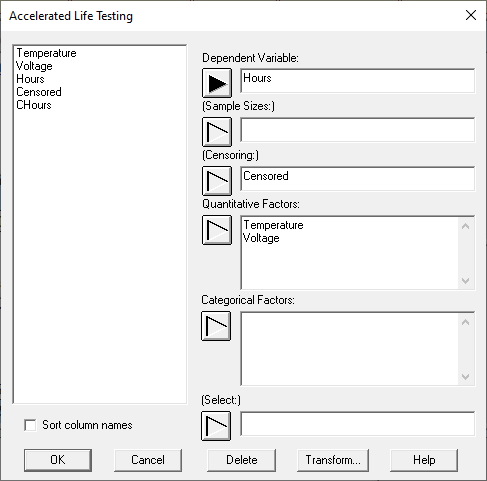
因变量是单个故障时间的样本。它可能是:
1.普通的数值列。在这种情况下,“删失”字段用于指示该行是表示未删失的故障时间(通过输入 0 表示)、右删失时间(通过输入 1 表示)还是左删失时间(通过输入 -1 表示)。
2.一个特殊的删失数字列。在这种情况下,“因变量”字段用于指示该行是否表示未删失故障时间(通过输入数字(如 475)表示)、右删失时间(通过输入表达式(如 >500)表示)、左删失时间(通过输入表达式(如 <50)表示)或间隔删失观测值(通过输入表达式(如 [300,350])表示)。不使用“审查”字段。
如果多个样本具有相同的特征,例如上面所示的数据文件的前 3 行,则样本大小字段可用于指定文件每行所表示的样本数。
定量因子和分类因子字段指定预测变量。必须至少有 1 个定量因子,输入的第一个因子被认为是主要的加速因子(在本例中为温度)。如下图所示,可以为主要因素选择各种加速度模型。其他因素(如电压)将作为线性项输入到回归模型中。如果需要其他因子的倒数模型,请在数据输入对话框中输入表达式(如 1/电压)。
分析选项
指定输入数据后,将显示“分析选项”对话框。
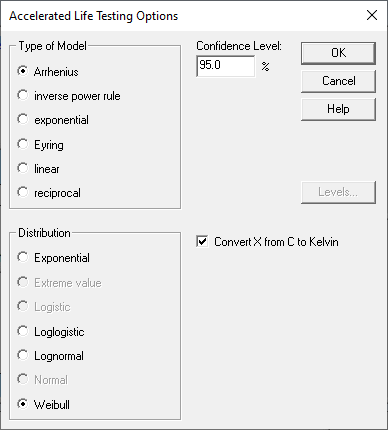
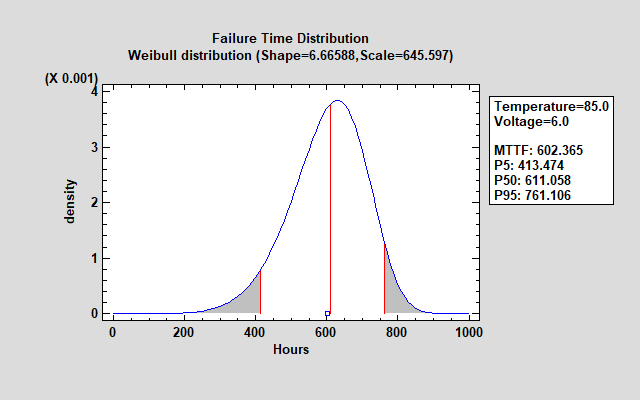
此对话框用于选择主因子的加速度模型类型。它还用于选择故障时间的分布。根据所选的分布,必须估计许多参数。例如,Weibull 分布有 2 个参数:形状参数和尺度参数。假定 shape 参数具有不依赖于预测变量的常量值。另一方面,尺度参数的值会随着预测变量的函数而变化。典型的 Weibull 分布如下所示:
分析摘要
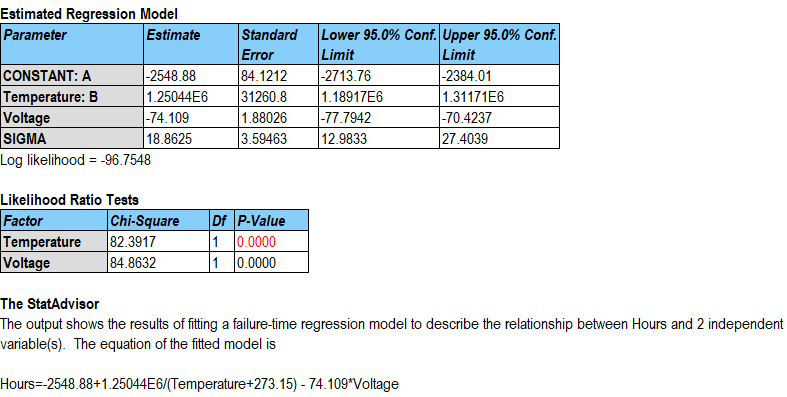
将请求的模型拟合到数据会生成显示拟合模型的分析摘要。示例数据的摘要如下所示:
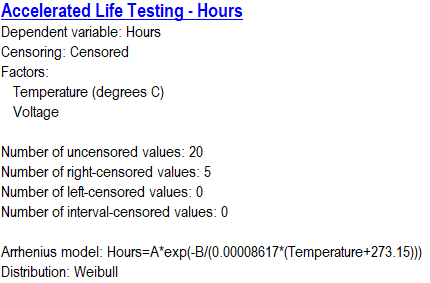
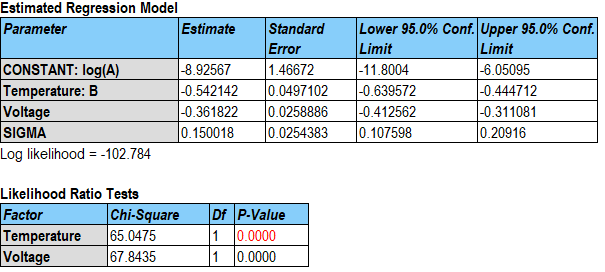

log(Hours) 的估计模型涉及将温度转换为开尔文度后的倒数值和电压的线性函数。任一预测变量的增加都会导致对 log(Hours) 的预测值降低。还估计了一个附加参数sigma,它与失效时间分布的离散有关。
故障时间分布
假设样本数据的故障时间分布遵循 Weibull 分布,该分布具有以下 pdf:
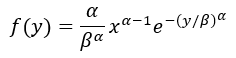
其中 a 是形状参数,b 是缩放参数。对于预测变量的任意组合,可以通过求解以下方程来确定参数:

可以看出,尺度参数是预测变量的函数,而形状参数不是。shape 参数仅与 s 相关。
对于其他分布,可以推导出类似的方程。
模型验证
在接受加速寿命测试的结果之前,重要的是要检查所选模型和失效时间分布与观测数据的拟合程度。为此,有两个图很有用。第一个图显示了所选模型预测的观察到的故障时间(不包括任何删失数据)的图。示例数据的图如下所示:
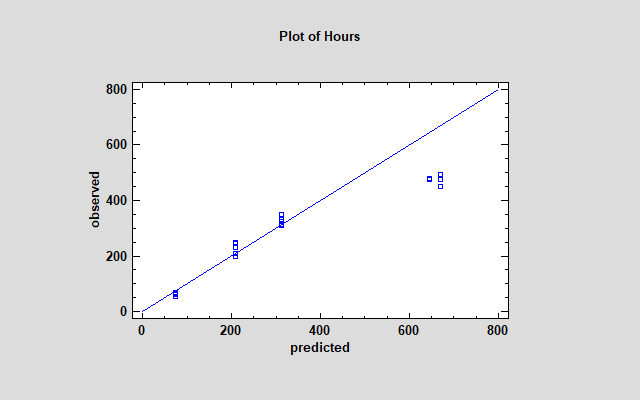
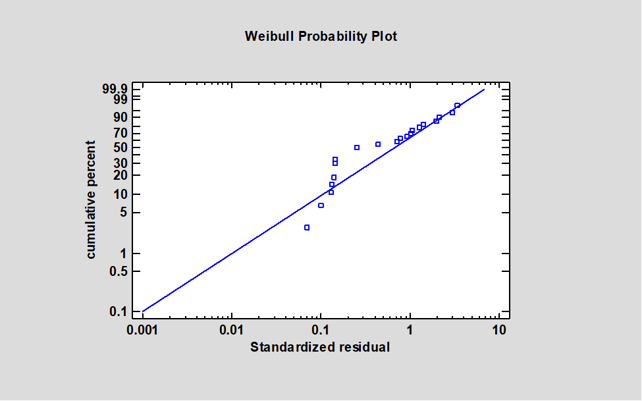
在较大的小时值下,预测值与对角线的偏差表明,该模型高估了最高观测值的故障时间。基于 Weibull 分布的残差概率图表明,该分布不能很好地预测数据,因为这些点明显偏离了对角线:
使用具有极值故障时间分布的倒数模型进行其他模型的试验显示出更好的结果:
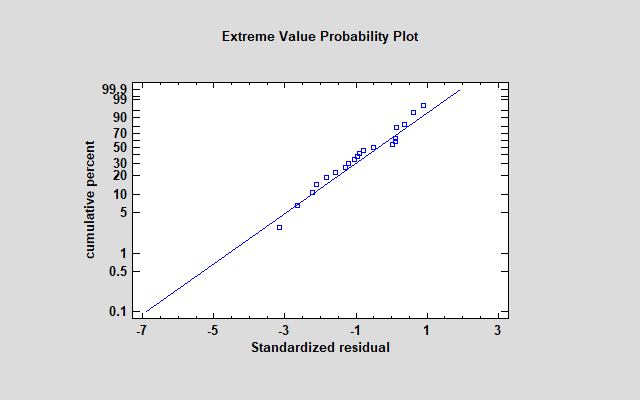
同样,两个预测变量都非常显著:
最小极值分布由 2 个参数定义:众数和尺度参数。众数等于拟合方程生成的值 m,而尺度参数等于 s。
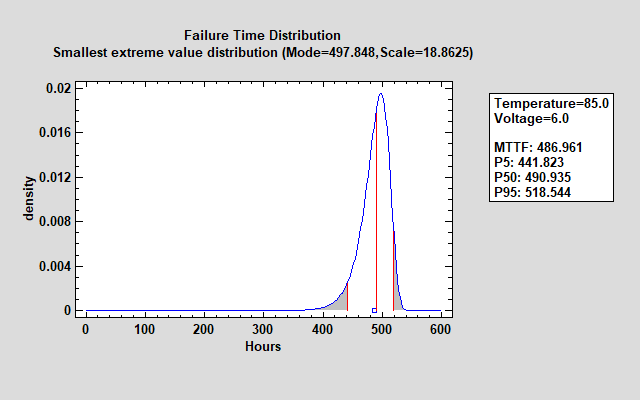
上图所示的故障时间分布比早期的 Weibull 分布要紧密得多。
外推法
为了估计温度 = 25 和电压 = 4 的正常工作条件下的故障时间分布,可以使用上面显示的公式来估计故障时间分布,如下所示:
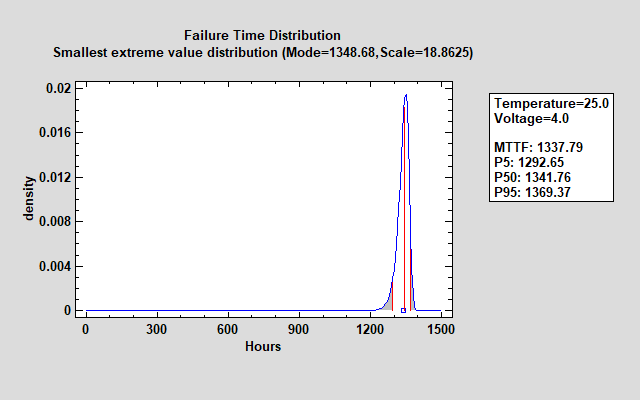
该预测变量组合的平均故障时间 (MTTF) 估计略高于 1,300 小时。90% 的分布位于大约 1,292 到 1,369 小时之间,如估计的百分位数所示。
还可以计算百分位数和平均故障时间的置信限。
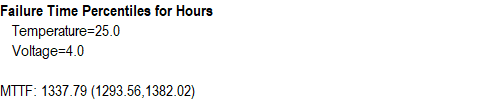
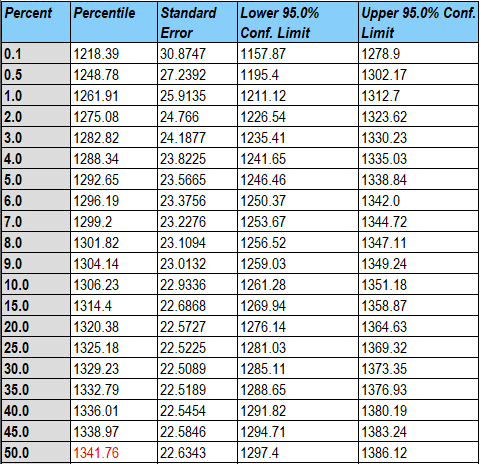
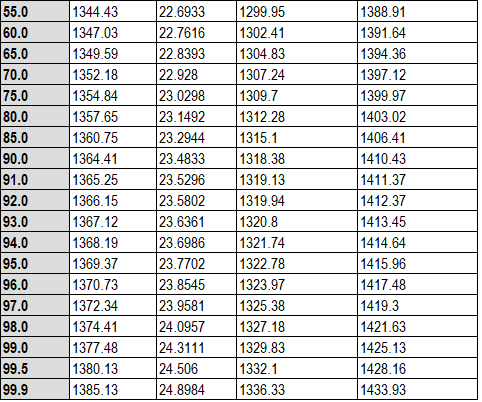
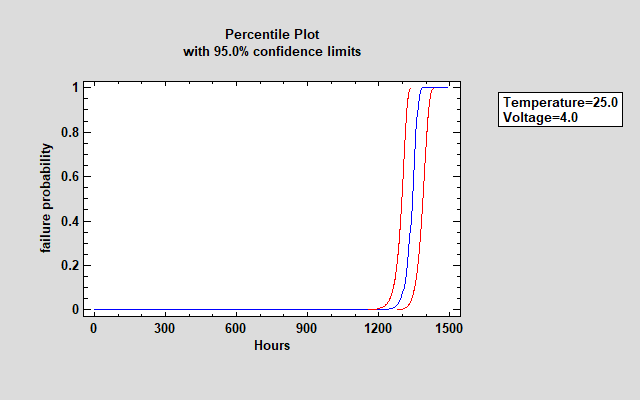
百分位数和置信限也可以以图形方式显示。
结论
加速寿命测试可以估计应力因素组合的失效时间分布,而实验是不切实际的。显然,结果取决于所选的加速度模型和假设的故障时间分布。在可能的情况下,这些决定应该在查看已发表的类似研究结果后做出,并通过检查当前数据进行验证。