数据挖掘是指从数据中提取模式的过程。此类模式通常提供对可用于改进业务决策的关系的洞察。统计数据挖掘工具和技术可以根据其用于聚类、分类、关联和预测的用途进行粗略分组。
| 程序 | Statgraphics Centurion 18/19 | Statgraphics Sigma express | Statgraphics stratus | Statgraphics Web 服务 | StatBeans |
|---|---|---|---|---|---|
| 聚类 |  | ||||
| 分类 | | ||||
| 联合 | | | | | |
| 预测 | | ||||
| 分类和回归树 | | ||||
| 文本挖掘 | | ||||
| 决策森林(仅限 V19) | | ||||
| K 均值聚类(仅限 V19) | |
聚类
聚类是指数据挖掘工具和技术,通过这些工具和技术,根据测量到的特征将一组案例放入自然分组中。由于特征的数量通常很大,因此需要采用案例之间相似性的多变量度量。在寻找如何进行数据挖掘时,Statgraphics 提供了多种导出聚类的方法,包括最近邻法、最远邻法、质心法、中位数法、组平均法、Ward 法和 K 均值法。结果可以显示为树状图、隶属关系表或冰柱图。聚集图用于建议适当的簇数。

更多:聚类分析.pdf
分类
分类是数据挖掘工具和技术之一,通过它根据一组案例的特征将其分配到分类因素的级别。已知案例的训练集用于开发分类算法,然后可用于预测未知案例最有可能属于哪个类别。例如,根据先前申请人开发的算法,贷款申请人可能会根据其个人特征被分为风险类别。
Statgraphics 中的神经网络分类器使用基于非参数密度函数估计与贝叶斯先验相结合的方法。

更多:神经网络分类器.pdf
联合
关联度量用于识别彼此相关的变量。如果这些因素是定量的,则相关系数可用于此类统计数据挖掘工具和技术。如果因素是非定量的,则使用其他关联度量来考虑如何进行数据挖掘。具有非线性 Lowess 平滑器的矩阵图如下所示。
Statgraphics 包括 Pearson 乘积矩相关系数、Kenkall 和 Spearman 等级相关、偏相关、lambda、不确定性系数、Somer’s D、列联系数、eta、Cramer’s V、条件 gamma、Pearson’s R 和 Kendall’s tau 等统计数据。

预测
预测是指开发统计模型,可以在给定其他变量值的情况下预测一个变量的值。数据挖掘工具和技术中经常使用各种类型的回归模型。当预测变量的数量很大时,选择一个好的模型可能很困难。在 Statgraphics 中,统计数据挖掘的回归模型选择过程拟合涉及一组预测变量的所有可能线性组合的模型,所有模型均使用 Mallows Cp 和调整后的 R 平方统计量等标准选择最佳模型。

更多:回归模型选择.pdf
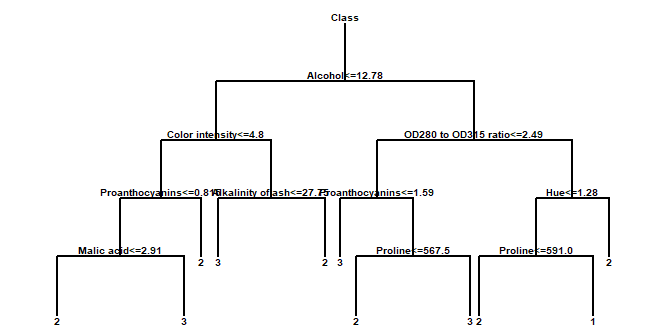
分类和回归树
分类和回归树过程实现了机器学习过程来预测数据中的观察结果。它创建两种形式的模型:
- 根据观察到的特征将观察结果分组的分类模型。
- 预测因变量值的回归模型。
该模型是通过创建一棵树来构建的,该树的每个节点对应于一个二元决策。给定一个特定的观察结果,人们沿着树的树枝向下移动,直到找到终止叶子。树的每个叶子都与预测的类别或值相关联。

更多信息: 分类和回归树.pdf 或观看分类树视频 或观看回归树视频
文本挖掘
文本挖掘过程分析一个或多个文本列或文档以确定各种单词的使用频率。该过程的主要输出是识别最常出现的单词。提供表格和图形摘要。

决策森林(版本 19)
决策森林过程实施机器学习过程来根据数据预测观察结果。它创建两种形式的模型:
- 根据观察到的特征将观察结果分组的分类模型。
- 预测因变量值的回归模型。
这些模型是通过创建大量决策树并对这些树的预测进行平均来构建的。许多树是使用类似于分类和回归树的过程构建的,具有随机节点优化和“装袋”。
K 均值聚类(版本 19)
K均值聚类过程实施机器学习过程来创建多元定量变量的组或聚类。聚类是通过对输入变量空间中靠近的观测值进行分组来创建的。与上面列出的聚类分析过程不同,用户不必为每个聚类指定初始种子。
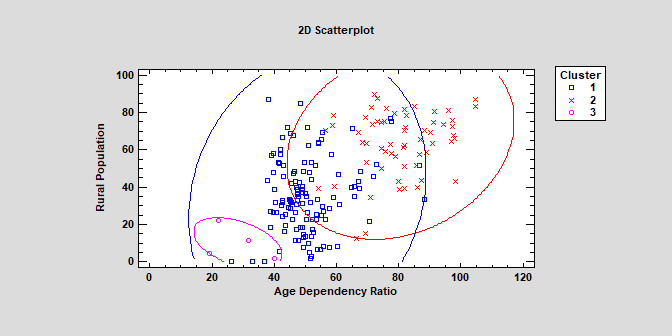
更多信息: K-Means Clustering.pdf或观看视频